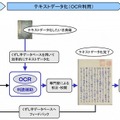
凸版印刷は3日、江戸期以前のくずし字を判別し、テキストデータ化するOCR(光学文字認識)技術を開発したことを発表した。本技術を使った古典籍のテキストデータ化サービスを、夏より試験的に提供開始する。 総数100万点以上ともいわれる古典籍は、専門家による判読が必要とされ、テキストデータ化が遅れていた。一方、凸版印刷は、2013年から「高精度全文テキスト化サービス」を提供開始。このサービスで確立したシステム基盤に、はこだて未来大学の寺沢憲吾准教授が開発した「文書画像検索システム」を組み合わせ、くずし字のOCRを実現した。 2014年度に実施した原理検証実験では、くずし字で記されている書物を80%以上の精度でOCR処理することに成功したという。これにより、専門家による判読に頼っていたテキストデータ化と比べ、大幅なコスト削減と大量処理が可能となる見込みだ。今後は、幅広い年代やジャンルの資料に対するOCR処理の精度向上を目指す。