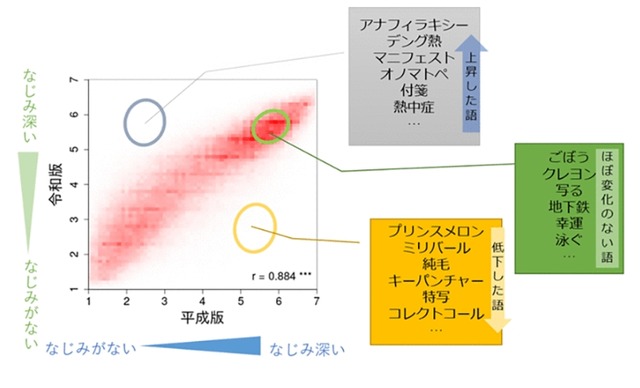
日本電信電話(NTT)は2020年6月3日、約16万3千語からなる「令和版単語親密度データベース」の構築と、「令和版語彙数推定テスト」を作成したと発表した。効果的な学習支援の実現をめざすという。 NTTは20年以上前から、単語のなじみ深さを示す「単語親密度」などの基盤的言語資源の構築に取り組んできた。過去に調査した約7万7千語からなる平成版の単語親密度データベースは、NTTデータベースシリーズ「日本語の語彙特性」として公開され、活用されてきた。しかし、調査から時間が経ち、単語親密度自体が時代とともに変化している可能性や、「インターネット」や「コンビニ」など新しく出現した語に対応していないなどの問題があった。また、これまでは児童・生徒を対象とした語彙数調査はほとんど実施されておらず、児童・生徒の語彙数調査方法の確立が求められていた。 そこで、単語親密度のデータベースを更新し、約16万3千語からなる「令和版単語親密度データベース」を構築。公立の小中高校生を含む約4,600人の語彙数調査を実施し、各学年・年齢における語彙獲得状況を、単語親密度に対応付けてモデル化した。これらの分析結果を反映し、令和版語彙数推定テストを作成した。 今後は、自治体と協力して語彙数調査を実施し、学童期からの調査をより広範に進める。学校での調査用とは別に、一般人向け令和版語彙数推定テストも公開予定。さらに、語彙数と読解力や学力全般との関係の調査・分析を行い、効果的な学習支援の実現をめざす。
【大学受験2027】清泉大、CBTを「期間随時開催方式」で導入…全国テストセンターで受験可能 2026.7.22 Wed 9:15 プロメトリックとGakkenは2026年7月21日、清泉大学の2027年度…